
Imagine you are going to build an online trading platform like Robinhood. You decide to use a single stateful server, such as a PostgreSQL database, to store trading information, and multiple stateless servers, such as trading service REST APIs, to handle user requests. In this approach, the business logic is implemented in the stateless component which helps us to expose functionality to the end users, and the data layer is implemented in the stateful component, which is managed by the database. Your architecture might look like this:
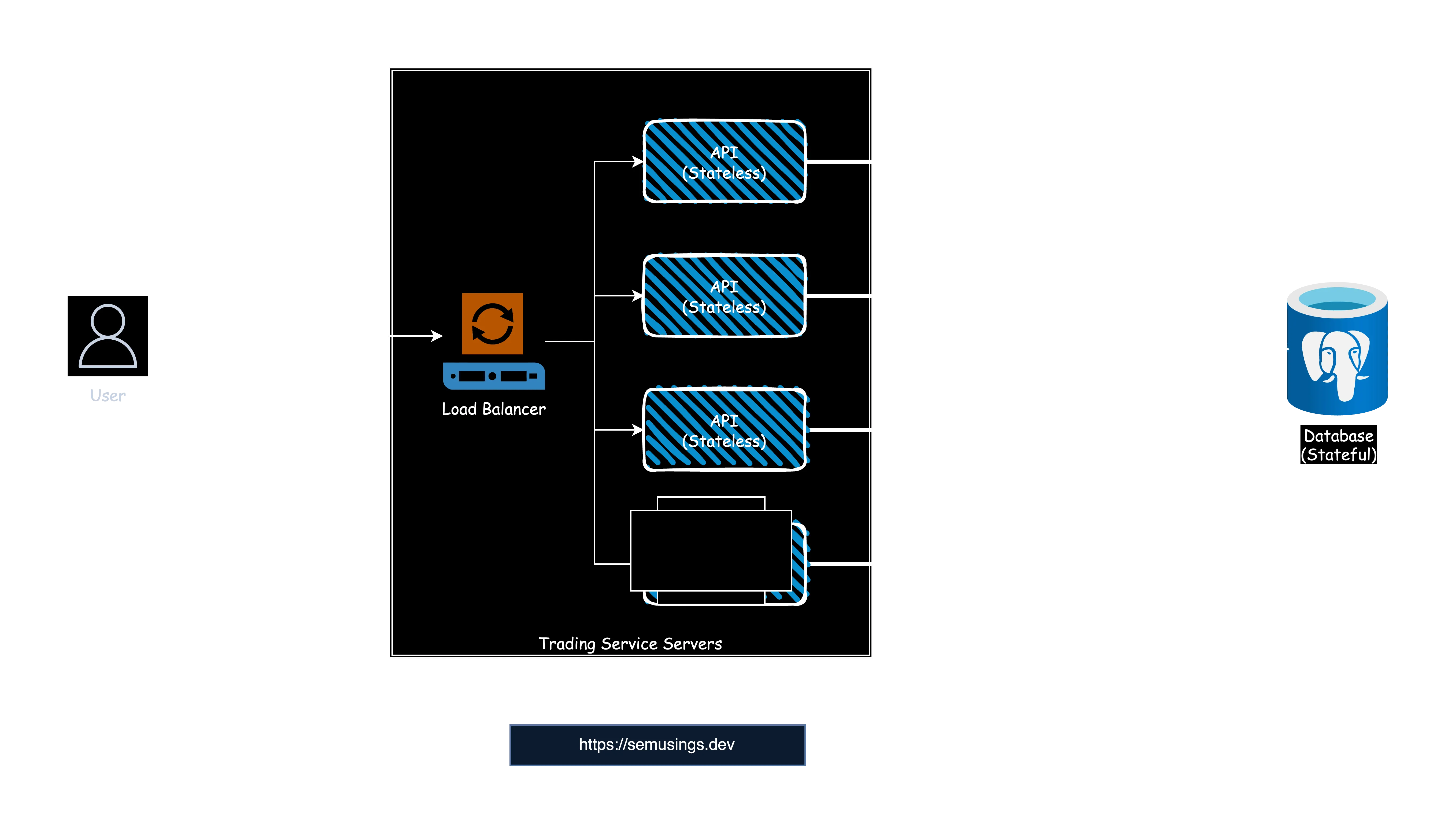
Initially, this system can handle the load effectively. However, as the user base grows and data accumulates over time, this architecture encounters limitations. The CPU, memory, and network connection of the stateful server become single points of failure, even with horizontal scaling of the service APIs.
For higher scalability, we need to ensure that both the stateful and stateless components are distributed.
Distributed systems stand on the principle of dividing tasks and data across multiple servers to improve performance, reliability, and scalability. By distributing both the stateful and stateless components, we can achieve higher fault tolerance and better resource utilization.
- The stateful components, such as databases, can be sharded (partitioned) or replicated across multiple nodes. This helps in balancing the load and ensuring that no single node becomes a bottleneck.
- The stateless components, such as service APIs, can be scaled horizontally by adding more instances to handle the increasing number of requests.
To summarize, effective scaling requires a holistic approach where both the stateful and stateless components are distributed and managed efficiently.